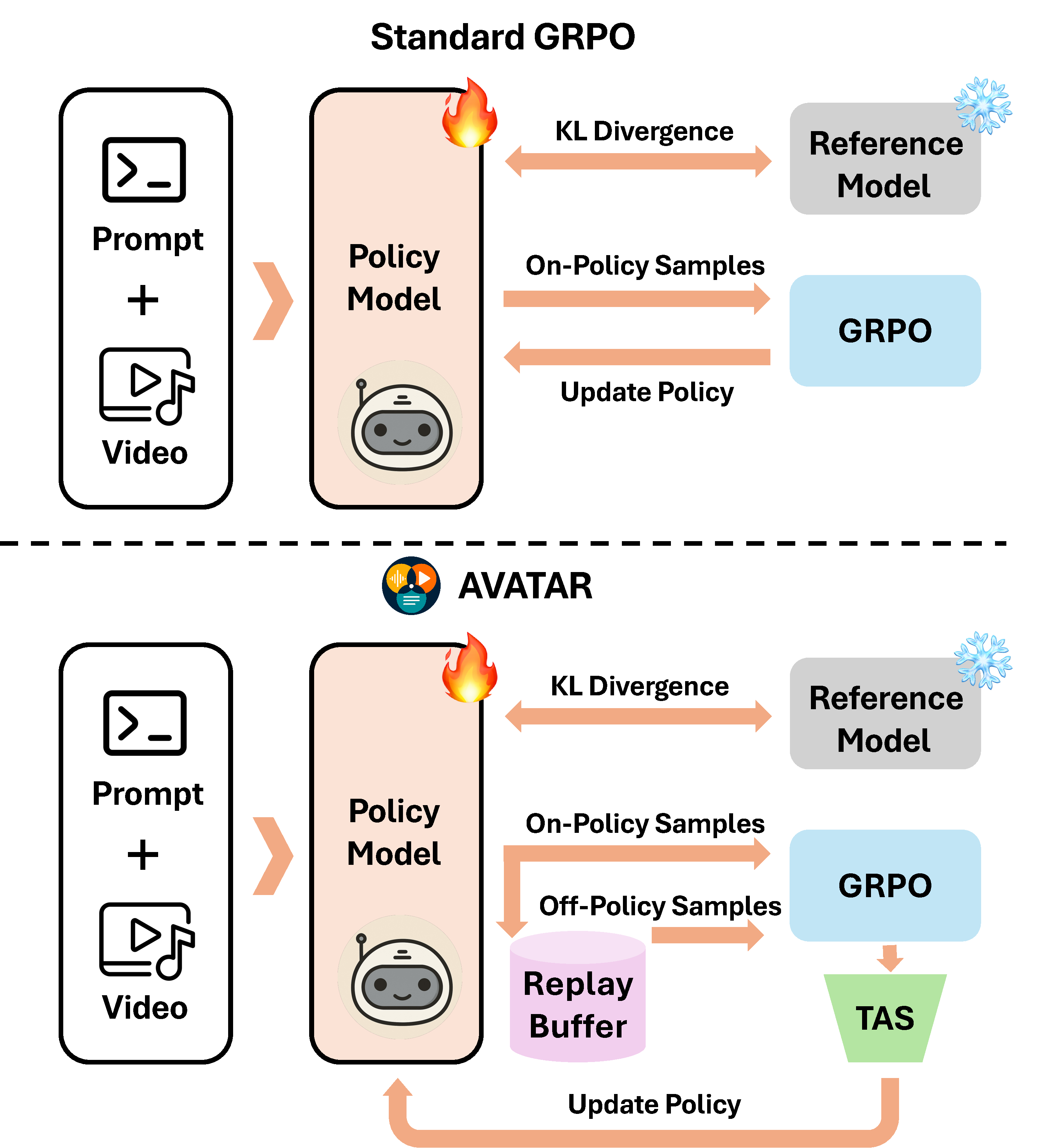
Multimodal reasoning over long-horizon video is challenging due to the need for precise spatiotemporal fusion and alignment across modalities. While recent methods such as Group Relative Policy Optimization (GRPO) have shown promise in this domain, they suffer from three key limitations: (1) data inefficiency from their on-policy design, (2) a vanishing advantage problem, where identical or near-identical rewards within a group eliminate the learning signal by producing zero-valued advantages, and (3) uniform credit assignment that fails to emphasize critical reasoning steps.
We introduce AVATAR (Audio-Video Agent for Alignment and Reasoning), a framework that addresses these limitations through two core components: (1) an off-policy training architecture that improves sample efficiency and resolves vanishing advantages by reusing past experiences with greater reward diversity, and (2) Temporal Advantage Shaping (TAS), a credit assignment strategy that emphasizes early (planning) and late (synthesis) reasoning phases.
AVATAR achieves strong performance across various benchmarks, outperforming the Qwen2.5-Omni baseline by +5.4 on MMVU, +4.9 on OmniBench, and +4.5 on Video-Holmes. Furthermore, it surpasses standard GRPO by +3.7 on OmniBench and +1.9 on Video-Holmes, while demonstrating 5× sample efficiency, requiring 80% fewer generated completions to reach target performance.
AVATAR employs a stratified replay buffer B (size 10k) divided into three tiers: Easy (25%), Medium (35%), and Hard (40%). Tier assignment is driven by each prompt's moving average reward R̄(q) — the bottom 40% by score go to the Hard tier, ensuring the model repeatedly engages with its hardest failure modes. A balanced 4 on-policy / 4 off-policy split per group empirically maximizes performance.
When a prompt remains in the Hard tier and KL divergence from the behavior policy drops (policy stops exploring), a pre-computed hint is injected — a short strategic suggestion (e.g., "first locate the object making the sound, then count") generated by a teacher model from full problem context. This unlocks the hardest 20% of the distribution that would otherwise yield zero reward.
TAS replaces GRPO's uniform credit assignment with a U-shaped parabolic weight. For a sequence of length L, each token at normalized position t̃ = t/(L−1) receives:
wt = 1.0 + λTAS · (2t̃ − 1)²
Minimal weight (1.0) at the middle; maximum weight (1.0 + λTAS) at the beginning (planning) and end (synthesis). No learned critic required.
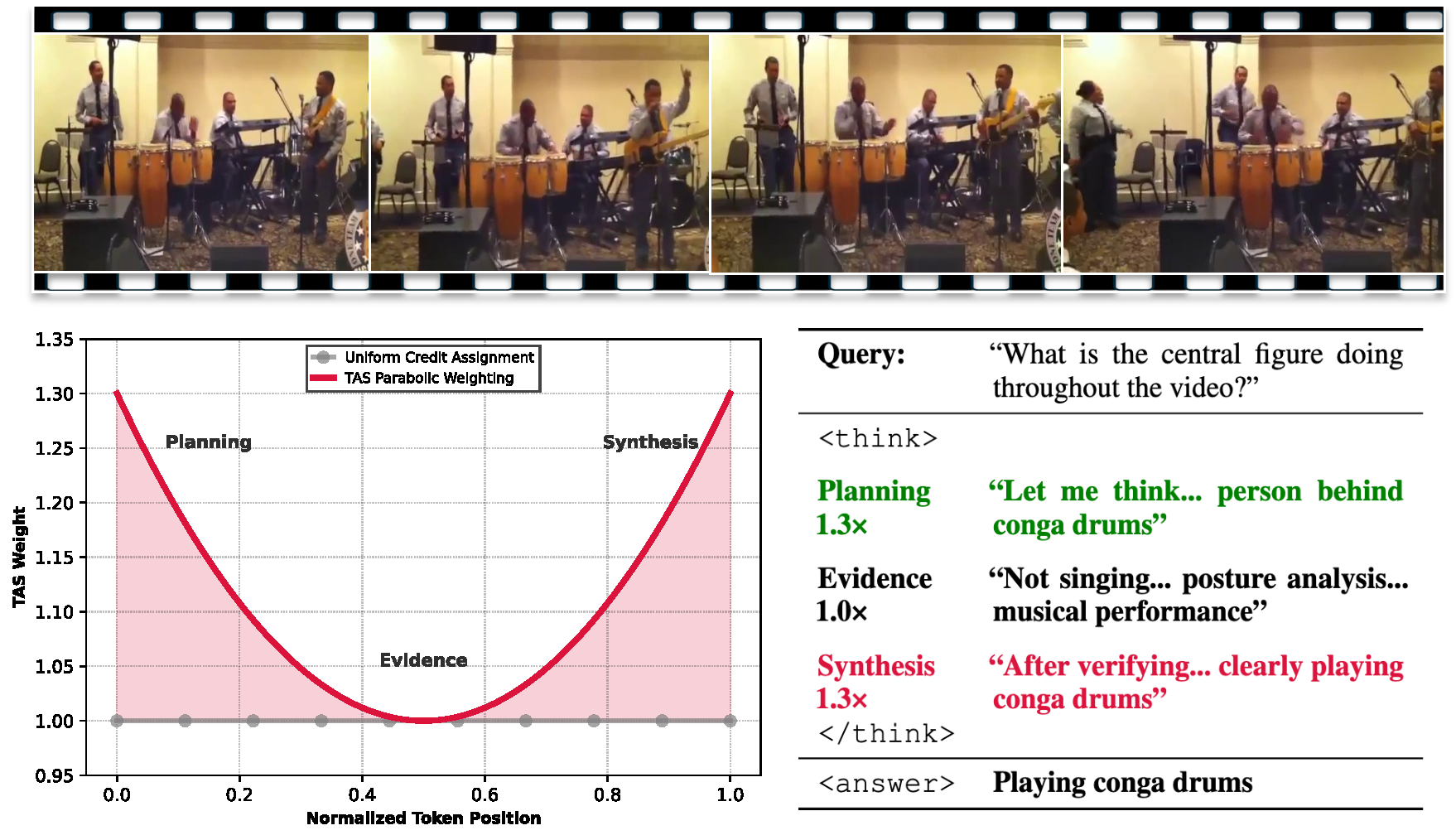
Figure 2. TAS U-shaped parabolic weight amplifies the planning (start) and synthesis (end) of each reasoning chain.
Stage 0: cold-start SFT. Stage 1: general visual reasoning. Stage 2: audio-visual alignment (audio captions from Kimi-Audio). Stage 3: fine-grained audio-based localization (stepwise judge reward from InternVL3). TAS is applied throughout all RL stages.
Figure 3. AVATAR's three-stage RL curriculum with progressively harder tasks and richer reward functions.
AVATAR vs. state-of-the-art audio-video understanding models. Gains shown in green with 95% CI. † not statistically significant.
| Model | OmniBench | DailyOmni | AV-Counting | AV-Odyssey | WorldSense | IntentBench |
|---|---|---|---|---|---|---|
| Ola-7B | ||||||
| Baseline | 45.3 | 52.3 | 17.4 | 25.6 | 44.2 | 59.1 |
| + GRPO | 46.8 (+1.5) | 54.1 (+1.8) | 18.2 (+0.8) | 27.0 (+1.4) | 44.7 (+0.5) | 60.3 (+1.2) |
| + AVATAR | 47.2 (+1.9) | 55.7 (+3.4) | 19.5 (+2.1) | 28.8 (+3.2) | 45.0 (+0.8) | 61.9 (+2.8) |
| Qwen2.5-Omni | ||||||
| Baseline | 44.2 | 44.0 | 22.3 | 29.8 | 44.2 | 63.7 |
| + GRPO | 45.4 (+1.2) | 44.8 (+0.8) | 22.8 (+0.5) | 31.3 (+1.5) | 45.1 (+0.9) | 63.8 (+0.1)† |
| + AVATAR | 49.1 (+4.9) | 47.0 (+3.0) | 23.1 (+0.8) | 32.1 (+2.3) | 46.0 (+1.8) | 63.9 (+0.2) |
AVATAR vs. state-of-the-art video models. † not statistically significant.
| Model | General Video Understanding | Video Reasoning | ||||
|---|---|---|---|---|---|---|
| MVBench | Video-MME | LVBench | Video-Holmes | MMVU | TOMATO | |
| Ola-7B | ||||||
| Baseline | 40.1 | 59.1 | 35.5 | 40.1 | 56.6 | 25.3 |
| + GRPO | 42.5 (+2.4) | 60.2 (+1.1) | 36.0 (+0.5) | 41.3 (+1.2) | 57.0 (+0.4) | 25.9 (+0.6) |
| + AVATAR | 45.4 (+5.3) | 61.4 (+2.3) | 36.6 (+1.1) | 42.4 (+2.3) | 57.3 (+0.7) | 26.6 (+1.3) |
| Qwen2.5-Omni | ||||||
| Baseline | 66.1 | 58.3 | 37.2 | 40.6 | 60.2 | 29.0 |
| + GRPO | 66.3 (+0.2) | 60.5 (+2.2) | 37.8 (+0.6) | 43.2 (+2.6) | 64.0 (+3.8) | 29.2 (+0.2)† |
| + AVATAR | 66.4 (+0.3)† | 62.8 (+4.5) | 38.4 (+1.2) | 45.1 (+4.5) | 65.6 (+5.4) | 30.8 (+1.8) |
GRPO's advantage distribution collapses to zero when all responses in a group receive similar rewards. AVATAR's stratified replay buffer mixes historically-hard and easy samples, shifting the distribution from a zero-centered spike to a bimodal shape.
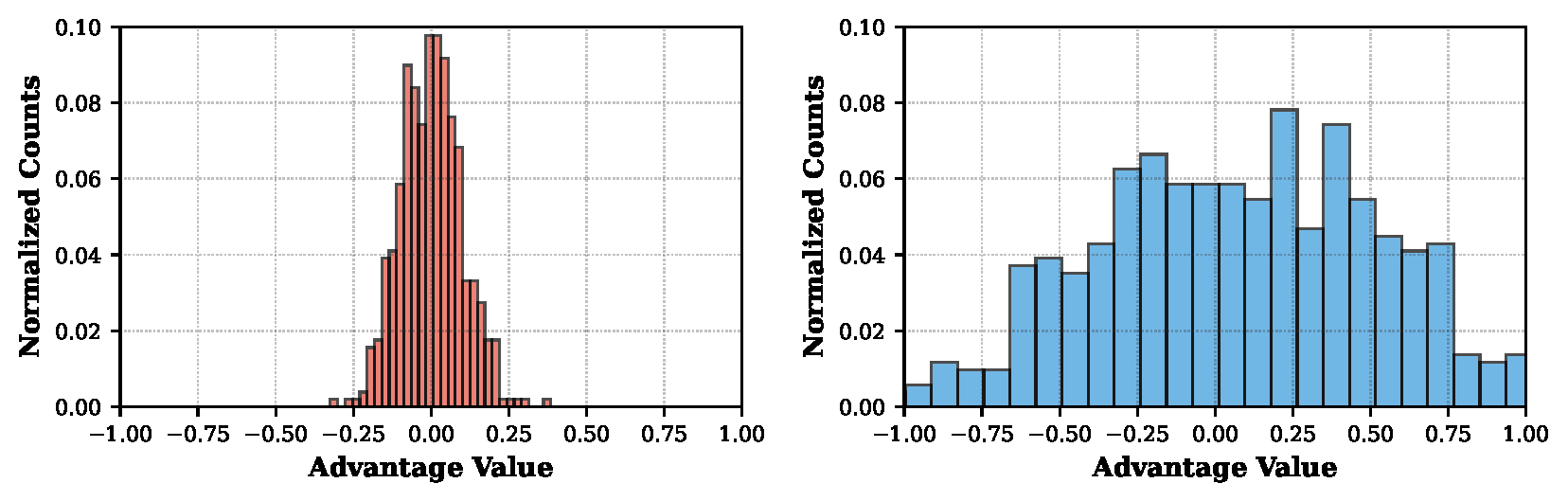
Figure 4. Advantage distribution under GRPO (left) collapses to zero. AVATAR (right) maintains a bimodal distribution enabling effective gradient flow.
AVATAR reaches 0.80 accuracy in 400 iterations (1,600 unique completions), while GRPO fails even after 1,000 iterations (8,000 completions) — 5× greater sample efficiency, requiring 80% fewer generated completions.
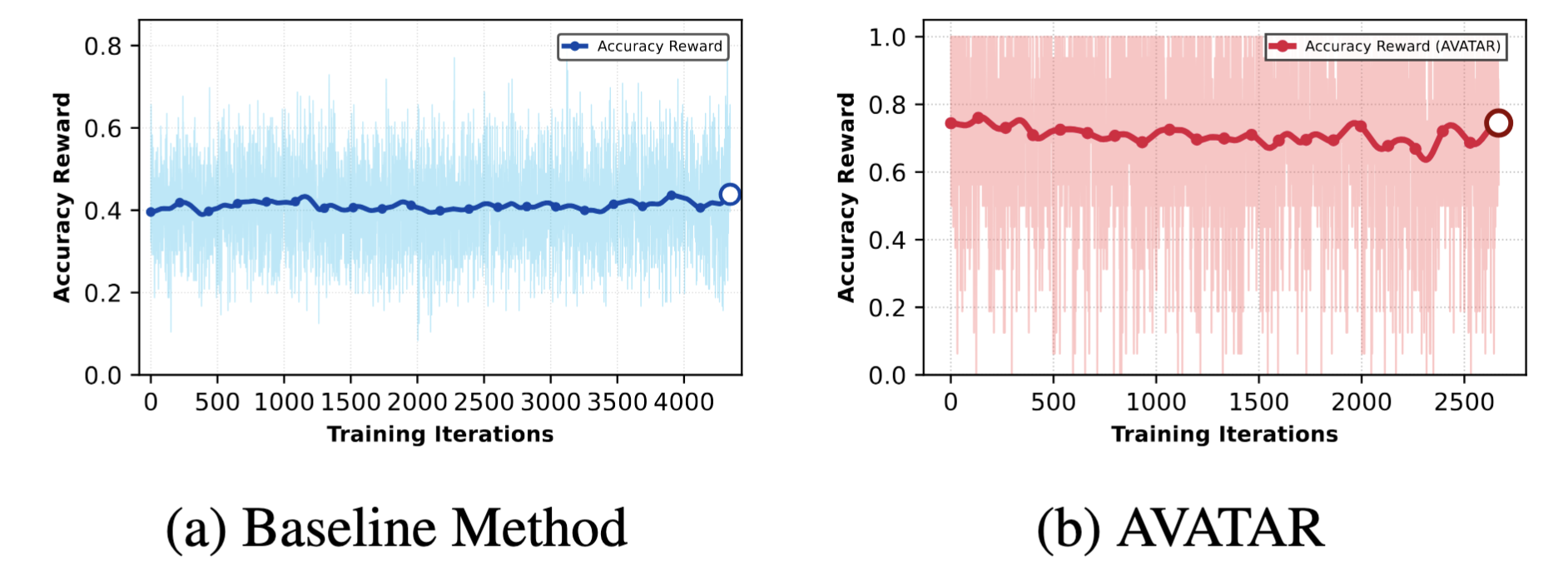
Figure 5. Training accuracy (left) and reward (right) over completions. AVATAR reaches target performance in 5× fewer samples than GRPO.
Each component addresses a specific GRPO limitation. Replay buffer resolves data inefficiency and vanishing advantages; TAS improves credit assignment; hinting escapes local optima.
| Qwen2.5-Omni | Audio-Visual | Video Reasoning | ||||
|---|---|---|---|---|---|---|
| OmniBench | DailyOmni | AV-Odyssey | Video-MMMU | VSI-Bench | Video-TT | |
| Baseline | 44.2 | 44.0 | 29.8 | 46.8 | 25.4 | 41.8 |
| + GRPO | 45.4 (+1.2) | 44.8 (+0.8) | 31.3 (+1.5) | 48.1 (+1.3) | 25.9 (+0.5) | 43.0 (+1.2) |
| + TAS Only (w/ On-Policy GRPO) | 45.1 (+0.9) | 45.4 (+1.4) | 31.4 (+1.6) | 49.0 (+2.2) | 26.5 (+1.1) | 43.8 (+2.0) |
| + Replay Buffer (w/ Uniform Credit) | 47.8 (+3.6) | 45.9 (+1.9) | 31.6 (+1.8) | 48.5 (+1.7) | 26.1 (+0.7) | 43.3 (+1.5) |
| + AVATAR (Full) | 49.1 (+4.9) | 47.0 (+3.0) | 32.1 (+2.3) | 49.4 (+2.6) | 26.8 (+1.4) | 44.2 (+2.4) |
Staged curriculum shows consistent stage-wise improvements. TAS (parabolic) outperforms all alternative weighting schemes including uniform, linear, and inverse parabolic.
| Setting | OmniBench | DailyOmni | AV-Odyssey | Video-Holmes | MMVU | TOMATO |
|---|---|---|---|---|---|---|
| Training Curriculum (Qwen2.5-Omni baseline: 44.2 / 44.0 / 29.8 / 40.6 / 60.2 / 29.0) | ||||||
| SFT Only | 45.8 (+1.6) | 45.2 (+1.2) | 30.1 (+0.3) | 41.8 (+1.2) | 62.1 (+1.9) | 28.9 (-0.1) |
| SFT + Stage 1 RL | 47.2 (+3.0) | 45.8 (+1.8) | 30.6 (+0.8) | 43.5 (+2.9) | 64.2 (+4.0) | 29.4 (+0.4) |
| SFT + Stages 1–2 RL | 48.6 (+4.4) | 46.7 (+2.7) | 31.8 (+2.0) | 44.2 (+3.6) | 65.1 (+4.9) | 30.1 (+1.1) |
| SFT + Stages 1–3 RL (AVATAR) | 49.1 (+4.9) | 47.0 (+3.0) | 32.1 (+2.3) | 45.1 (+4.5) | 65.6 (+5.4) | 30.8 (+1.8) |
| Advantage Shaping Strategy | ||||||
| Uniform (GRPO) | 47.8 (+3.6) | 45.9 (+1.9) | 31.6 (+1.8) | 43.7 (+3.1) | 64.8 (+4.6) | 29.3 (+0.3) |
| Inverse Parabolic | 46.5 (+2.3) | 45.1 (+1.1) | 30.8 (+1.0) | 42.8 (+2.2) | 63.5 (+3.3) | 29.1 (+0.1) |
| TAS — Parabolic (Ours) | 49.1 (+4.9) | 47.0 (+3.0) | 32.1 (+2.3) | 45.1 (+4.5) | 65.6 (+5.4) | 30.8 (+1.8) |
TAS consistently improves performance across reasoning lengths, with gains amplifying as sequences grow longer. The advantage is most pronounced for extended sequences (400+ tokens), particularly on challenging benchmarks like MMVU and Video-Holmes, where uniform credit would dilute the reward signal most severely.
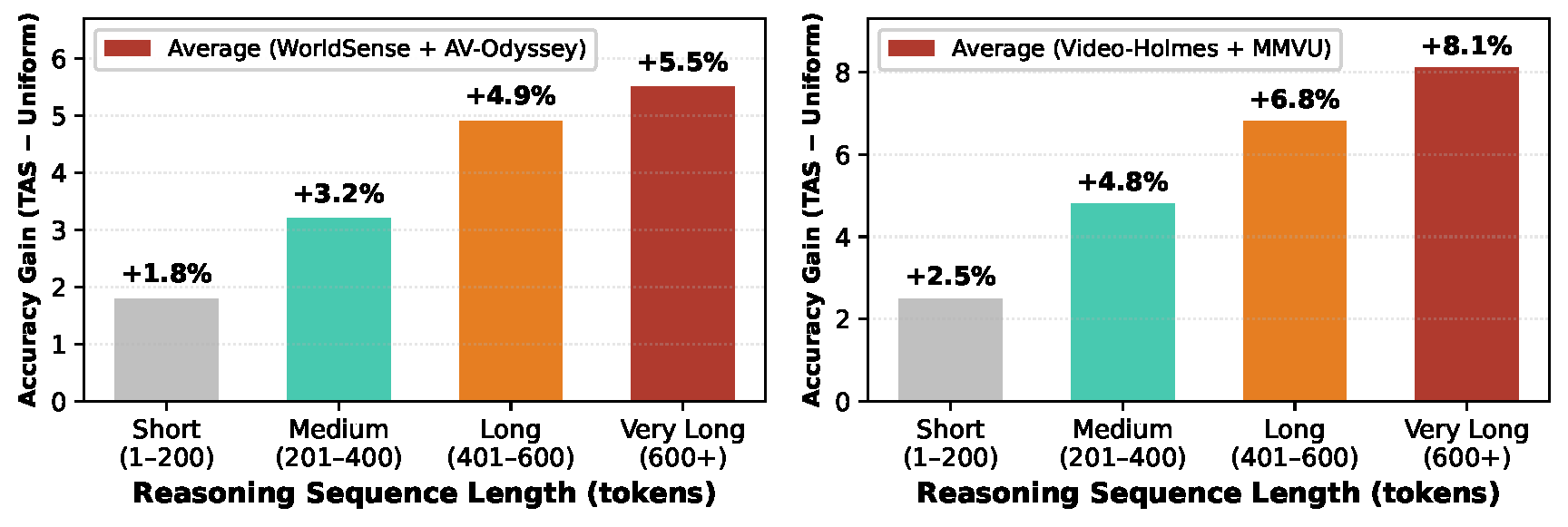
Figure 6. TAS improvement over GRPO vs. reasoning sequence length on audio-visual (left) and video reasoning (right) benchmarks.
AVATAR demonstrates superior cross-modal integration — linking visual cues ("tense expression, eyes darting around") with audio analysis ("hurried and tense tone when he speaks") — while baseline GRPO makes disconnected observations. AVATAR tracks emotional progression ("tone shifting from calm to anxious") and interprets precise dialogue ("Sorry, I have a train to catch" indicating abrupt departure), rather than falling back on surface-level genre classification.

Qualitative comparison of AVATAR vs. baseline GRPO on an audio-visual reasoning example from Video-Holmes.
@inproceedings{kulkarni2026avatar,
title={AVATAR: Reinforcement Learning to See, Hear, and Reason Over Video},
author={Kulkarni, Yogesh and Fazli, Pooyan},
booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}