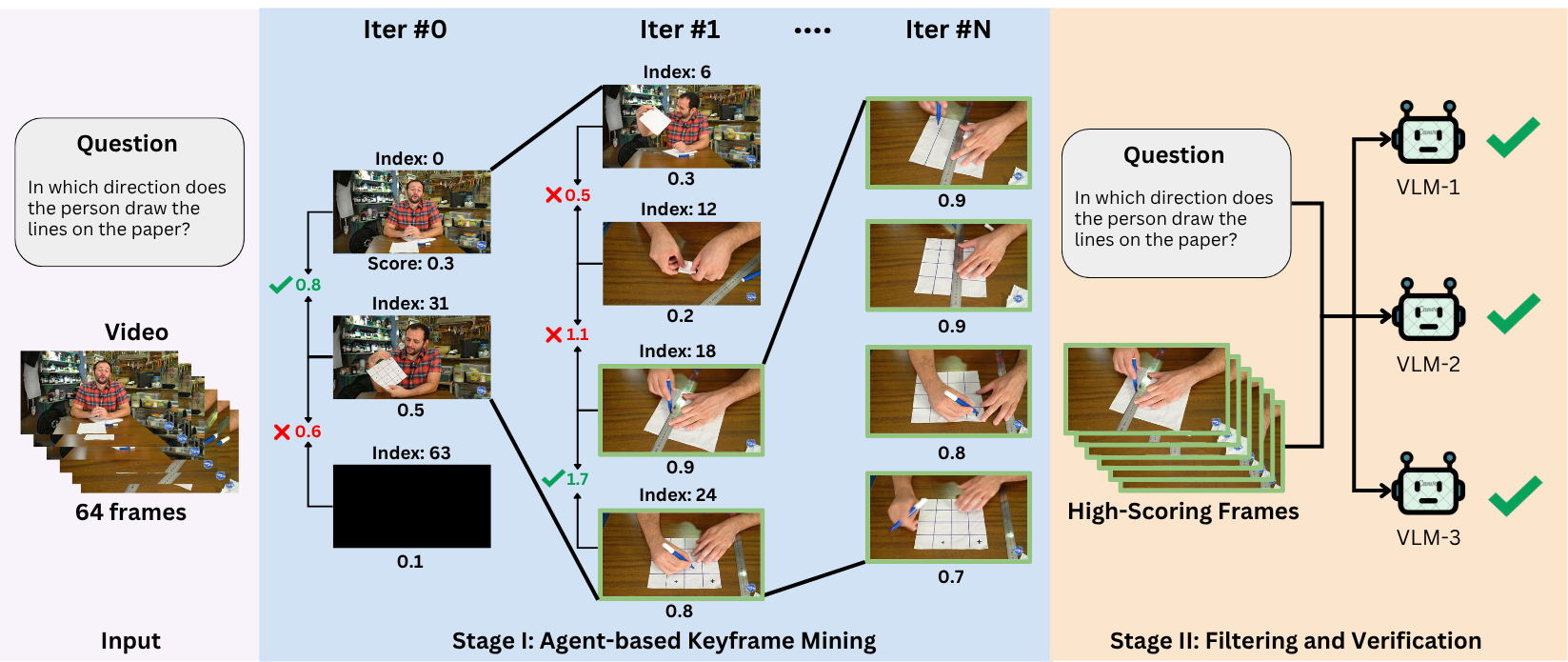
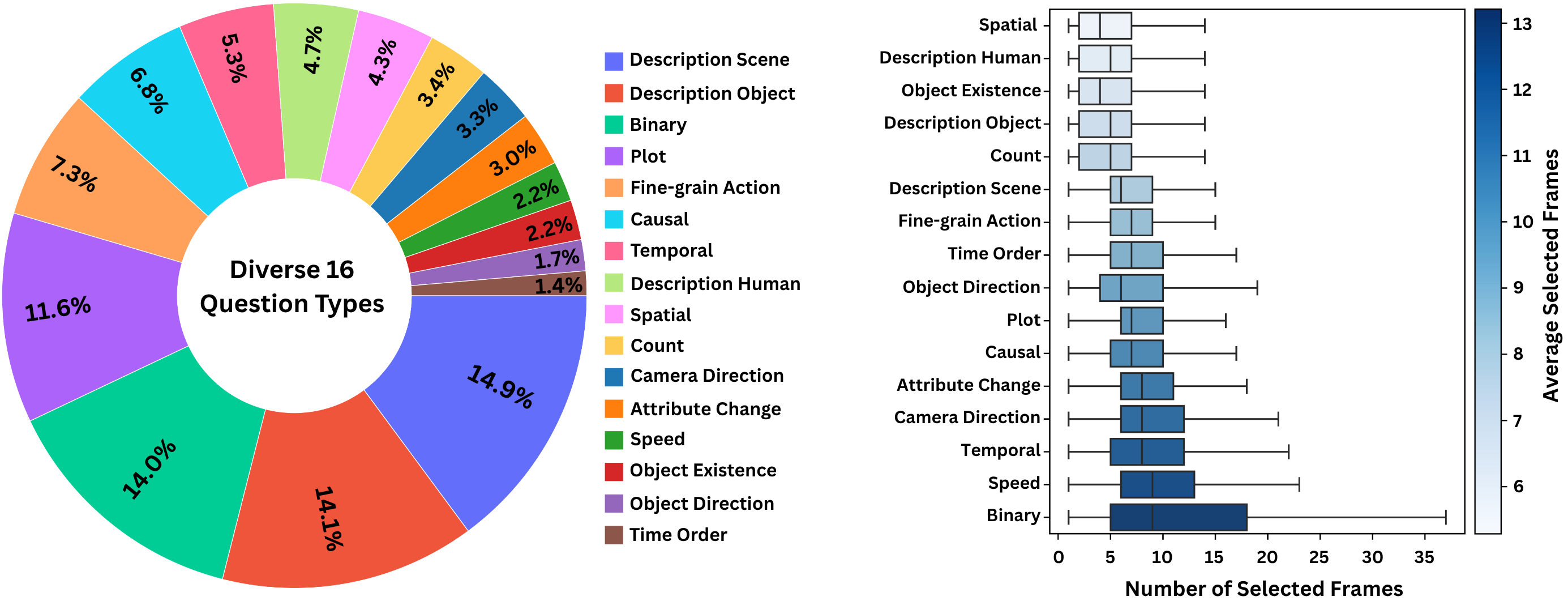
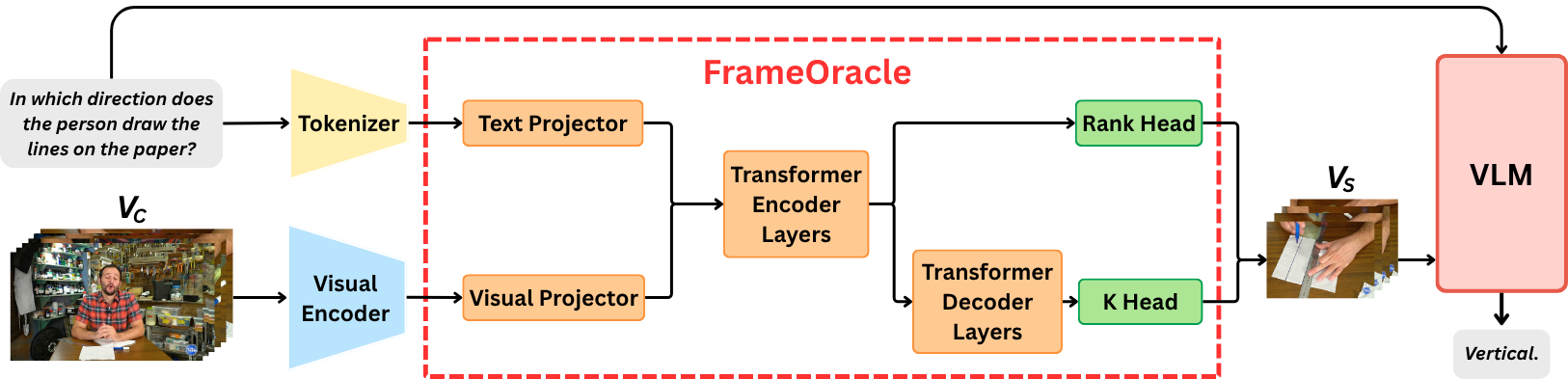
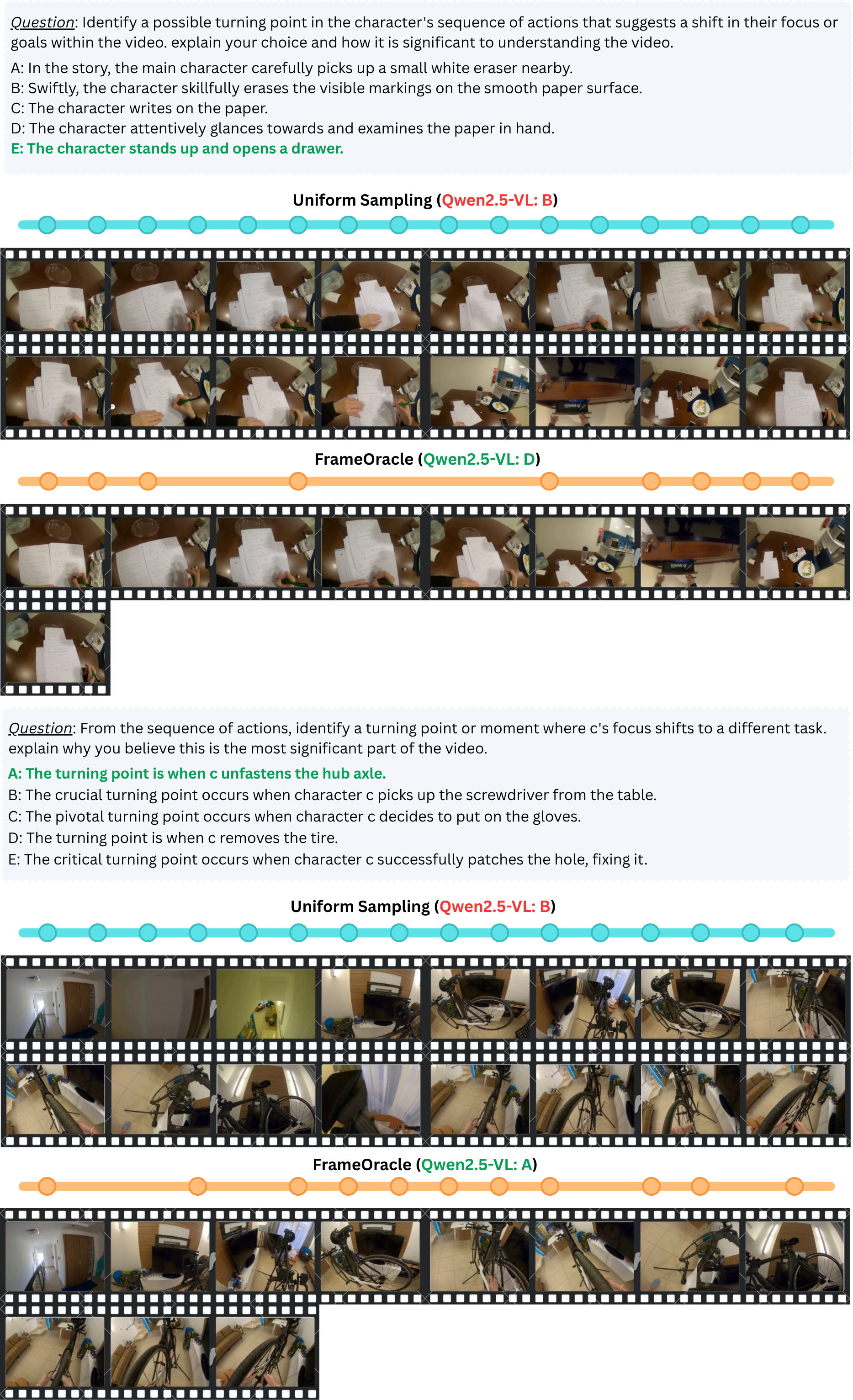
Video VLMs cannot always process all frames in a long video. A fixed number of frames is easy to use, but it ignores the fact that some questions require only a few key moments while others require broader temporal coverage.
FrameOracle turns frame selection into a learned, query-conditioned decision. Instead of asking the downstream VLM to reason over redundant or distracting frames, it provides a compact subset that is more likely to contain the necessary visual evidence.